在Java编程中,如何使用java从ODF文件中提取内容??
项目的目录结构如下 -

Tika的工具包可从以下网址下载:http://tika.apache.org/download.html ,只下载:tika-app-1.16.jar 和 tika-server-1.16.jar 。
以下是使用java从ODF文件中提取内容的程序 -
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.odf.OpenDocumentParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class ExtractContentFromODF {
public static void main(String[] args) throws Exception {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File(
"demODF.odt"));
ParseContext pcontext = new ParseContext();
//Open Document Parser
OpenDocumentParser openofficeparser = new OpenDocumentParser ();
openofficeparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}
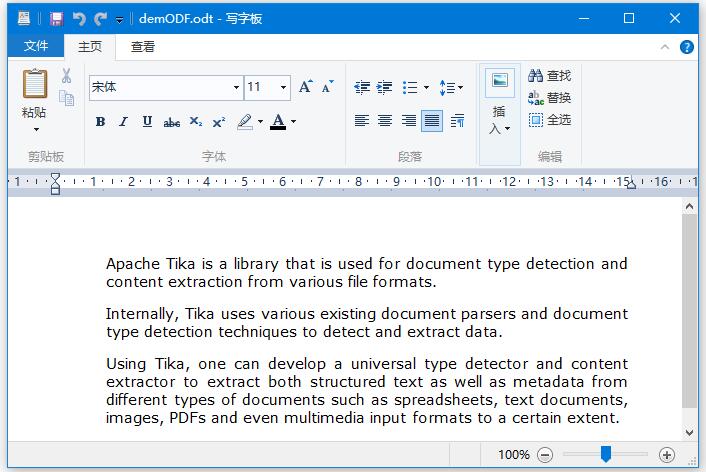
原ODF文件:demODF.odt 的内容如下 -
执行上面示例代码,得到以下结果 -
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/F:/worksp/javaexamples/libs/tika_libs/tika-app-1.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/F:/worksp/javaexamples/libs/tika_libs/tika-server-1.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
九月 27, 2017 4:59:52 上午 org.apache.tika.config.InitializableProblemHandler$3 handleInitializableProblem
警告: JBIG2ImageReader not loaded. jbig2 files will be ignored
See http://pdfbox.apache.org/2.0/dependencies.html#jai-image-io
for optional dependencies.
TIFFImageWriter not loaded. tiff files will not be processed
See http://pdfbox.apache.org/2.0/dependencies.html#jai-image-io
for optional dependencies.
J2KImageReader not loaded. JPEG2000 files will not be processed.
See http://pdfbox.apache.org/2.0/dependencies.html#jai-image-io
for optional dependencies.
九月 27, 2017 4:59:52 上午 org.apache.tika.config.InitializableProblemHandler$3 handleInitializableProblem
警告: org.xerial's sqlite-jdbc is not loaded.
Please provide the jar on your classpath to parse sqlite files.
See tika-parsers/pom.xml for the correct version.
Contents of the document:
Apache Tika is a library that is used for document type detection and content extraction from various file formats.
Internally, Tika uses various existing document parsers and document type detection techniques to detect and extract data.
Using Tika, one can develop a universal type detector and content extractor to extract both structured text as well as metadata from different types of documents such as spreadsheets, text documents, images, PDFs and even multimedia input formats to a certain extent.
Metadata of the document:
date : 2017-09-27T08:16:26
custom:DocSecurity : 0
meta:paragraph-count : 3
meta:word-count : 78
Table-Count : 0
meta:initial-author : Administrator
initial-creator : Administrator
dc:creator : Hema
generator : LibreOffice/5.4.1.2$Linux_X86_64 LibreOffice_project/ea7cb86e6eeb2bf3a5af73a8f7777ac570321527
Word-Count : 78
dcterms:created : 2014-10-29T12:08:00
dcterms:modified : 2017-09-27T08:16:26
Last-Modified : 2017-09-27T08:16:26
nbPara : 3
Last-Save-Date : 2017-09-27T08:16:26
meta:object-count : 0
meta:character-count : 504
Paragraph-Count : 3
nbImg : 0
meta:save-date : 2017-09-27T08:16:26
modified : 2017-09-27T08:16:26
meta:image-count : 0
Image-Count : 0
nbCharacter : 504
nbObject : 0
nbPage : 1
Object-Count : 0
nbWord : 78
custom:LinksUpToDate : false
Content-Type : application/vnd.oasis.opendocument.text
custom:KSOProductBuildVer : 2052-10.1.0.6489
creator : Hema
meta:author : Hema
meta:creation-date : 2014-10-29T12:08:00
meta:table-count : 0
custom:ScaleCrop : false
Creation-Date : 2014-10-29T12:08:00
xmpTPg:NPages : 1
Character Count : 504
Page-Count : 1
Author : Hema
nbTab : 0
meta:page-count : 1
