在Spark中,Intersection函数返回一个新数据集,其中包含不同数据集中存在的元素的交集。因此,它只返回一行。此函数的行为与SQL中的INTERSECT查询类似。
Intersection函数示例
在此示例中,将两个数据集的元素相交。要在Scala模式下打开Spark,请按照以下命令操作。
$ spark-shell
使用并行化集合创建RDD。
scala> val data1 = sc.parallelize(List(1,2,3))
现在,可以使用以下命令读取生成的结果。
scala> data1.collect

使用并行化集合创建另一个RDD。
scala> val data2 = sc.parallelize(List(3,4,5))
`
现在,可以使用以下命令读取生成的结果。
scala> data2.collect

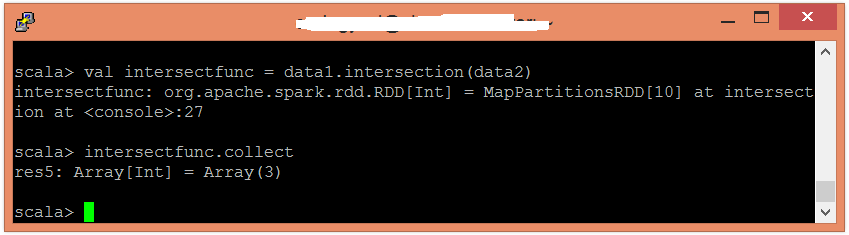
应用intersection()函数返回元素的交集。
scala> val intersectfunc = data1.intersection(data2)
现在,可以使用以下命令读取生成的结果。
scala> intersectfunc.collect